HUB Workflow Cookbook¶
General¶
Is HUB Workflow installed¶
Imports HUB Workflow and exits the program if the modules are not found.
import sys
try:
import hubflow.core
except:
sys.exit('ERROR: cannot find HUB Workflow modules')
Is the testdata installed¶
In this guide we use the EnMAP-Box testdata (https://bitbucket.org/hu-geomatics/enmap-box-testdata).
import sys
try:
import enmapboxtestdata
except:
sys.exit('ERROR: cannot find EnMAP-Box Testdata modules')
Check versions installed¶
import hubdc
import enmapboxtestdata
print(hubdc.__version__)
print(enmapboxtestdata.__version__)
Raster¶
Save raster to new location and specific format¶
import enmapboxtestdata
from hubflow.core import *
raster = Raster(filename=enmapboxtestdata.enmap)
# save raster with ENVI driver
copy = raster.saveAs(filename='raster.dat', driver=RasterDriver(name='ENVI'))
print(copy.dataset().driver())
# save raster with driver derived from file extension
copy2 = raster.saveAs(filename='raster.tif')
print(copy2.dataset().driver())
Prints:
RasterDriver(name='ENVI')
RasterDriver(name='GTiff')
Apply a spatial convolution filter¶
from astropy.convolution import Gaussian2DKernel, Kernel2D
import enmapboxtestdata
from hubflow.core import *
raster = Raster(filename=enmapboxtestdata.enmap)
# apply a Gaussian filter
kernel = Gaussian2DKernel(x_stddev=1, y_stddev=1, x_size=7, y_size=7)
print(np.round(kernel.array, 3))
filteredGaussian = raster.convolve(filename='filteredGaussian.bsq', kernel=kernel)
# apply a Highpass filter
kernel = Kernel2D(array=[[-1, -1, -1],
[-1, 8, -1],
[-1, -1, -1]])
print(kernel.array)
filteredHighpass = raster.convolve(filename='filteredHighpass.bsq', kernel=kernel)
Prints:
[[0. 0. 0.001 0.002 0.001 0. 0. ]
[0. 0.003 0.013 0.022 0.013 0.003 0. ]
[0.001 0.013 0.059 0.097 0.059 0.013 0.001]
[0.002 0.022 0.097 0.159 0.097 0.022 0.002]
[0.001 0.013 0.059 0.097 0.059 0.013 0.001]
[0. 0.003 0.013 0.022 0.013 0.003 0. ]
[0. 0. 0.001 0.002 0.001 0. 0. ]]
[[-1 -1 -1]
[-1 8 -1]
[-1 -1 -1]]

Result of Gaussian filter

Result of Highpass filter
Classification¶
Reclassify a classification¶
Merge 6 detailed landcover classes into a binary urban vs non-urban classification.
import enmapboxtestdata
from hubflow.core import *
# create test classification
classification = Classification(filename=enmapboxtestdata.createClassification(gridOrResolution=5, level='level_3_id', oversampling=1))
# reclassify
reclassified = classification.reclassify(filename='classification.bsq',
classDefinition=ClassDefinition(names=['urban', 'non-urban'], colors=['red', 'green']),
mapping={1: 1, 2: 1, 3: 2, 4: 2, 5: 2, 6: 2})
print(classification.classDefinition())
print(reclassified.classDefinition())
Prints:
ClassDefinition(classes=6, names=['roof', 'pavement', 'low vegetation', 'tree', 'soil', 'water'], colors=[Color(([230, 0, 0],)), Color(([156, 156, 156],)), Color(([152, 230, 0],)), Color(([38, 115, 0],)), Color(([168, 112, 0],)), Color(([0, 100, 255],))])
ClassDefinition(classes=2, names=['urban', 'non-urban'], colors=[Color(([255, 0, 0],)), Color(([0, 128, 0],))])
| ..... | Classes |
|---|---|
| roof | |
| pavement | |
| low vegetation | |
| tree | |
| soil | |
| water |
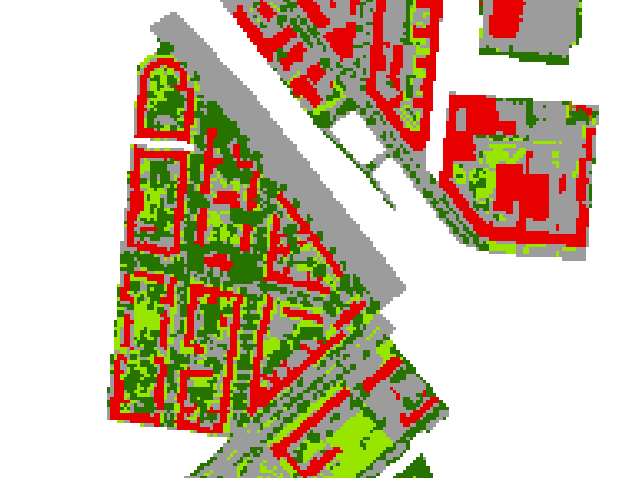
Original
| ..... | Classes |
|---|---|
| urban | |
| non-urban |
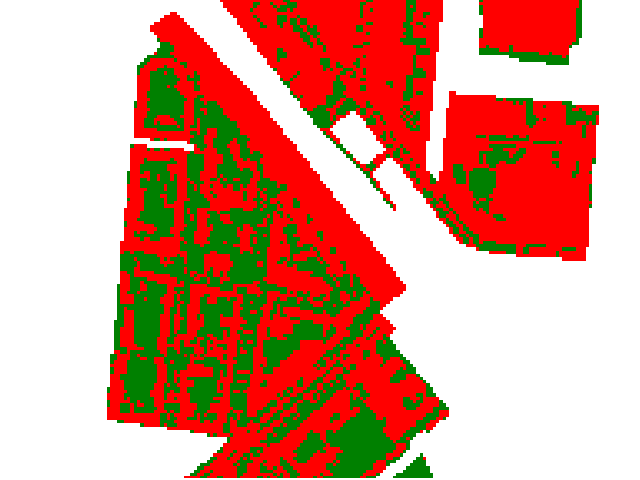
Reclassified
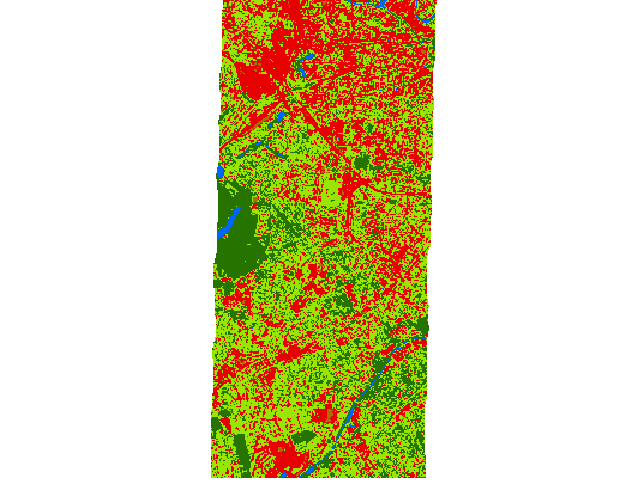
Fit Random Forest classifier, apply to a raster and assess the performance¶
import enmapboxtestdata
from hubflow.core import *
# create classification sample
raster = Raster(filename=enmapboxtestdata.enmap)
classification = Classification(filename=enmapboxtestdata.createClassification(gridOrResolution=raster.grid(), level='level_2_id', oversampling=5))
sample = ClassificationSample(raster=raster, classification=classification)
# fit classifier
from sklearn.ensemble import RandomForestClassifier
classifier = Classifier(sklEstimator=RandomForestClassifier(n_estimators=10))
classifier.fit(sample=sample)
# classify a raster
prediction = classifier.predict(filename='randonForestClassification.bsq', raster=raster)
# asses accuracy
performance = ClassificationPerformance.fromRaster(prediction=prediction, reference=classification)
performance.report().saveHTML(filename='ClassificationPerformance.html')
| ..... | Classes |
|---|---|
| impervious | |
| low vegetation | |
| tree | |
| soil | |
| water |
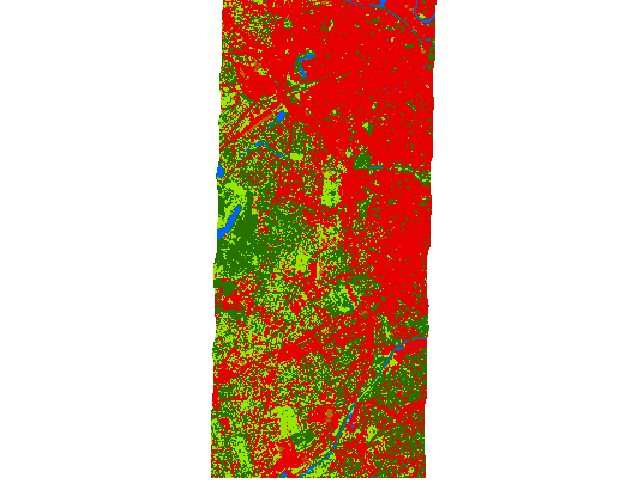
Random Forest Classification
HTML report:
Set class definition¶
from hubflow.core import *
# create a raster
Raster.fromArray(array=[[[0, 1, 2, 3]]], filename='classification.bsq')
# open the raster as classification in Update mode
classification = Classification(filename='classification.bsq', eAccess=gdal.GA_Update)
# set the class definition
classDefinition = ClassDefinition(classes=3, names=['c1', 'c2', 'c3'], colors=['red', 'green', 'blue'])
classification.setClassDefinition(classDefinition)
# re-open the classification (required!)
classification.close()
classification = Classification(filename='classification.bsq')
print(classification)
Prints:
Classification(filename=classification.bsq, classDefinition=ClassDefinition(classes=3, names=['c1', 'c2', 'c3'], colors=[Color(([255, 0, 0],)), Color(([0, 128, 0],)), Color(([0, 0, 255],))]), minOverallCoverage=0.5, minDominantCoverage=0.5)
| ..... | Classes |
|---|---|
| c1 | |
| c2 | |
| c3 |

Regression¶
Fit Random Forest regressor, apply to a raster and assess the performance¶
import enmapboxtestdata
from hubflow.core import *
# create (multi tagret) regression sample (labels are landcover class fractions)
raster = Raster(filename=enmapboxtestdata.enmap)
regression = Regression(filename=enmapboxtestdata.createFraction(gridOrResolution=raster.grid(), level='level_1_id', oversampling=5))
sample = RegressionSample(raster=raster, regression=regression)
# fit regressor
from sklearn.ensemble import RandomForestRegressor
regressor = Regressor(sklEstimator=RandomForestRegressor(n_estimators=10))
regressor.fit(sample=sample)
# regress a raster
prediction = regressor.predict(filename='randonForestRegression.bsq', raster=raster)
# asses accuracy
performance = RegressionPerformance.fromRaster(prediction=prediction, reference=regression)
performance.report().saveHTML(filename='RegressionPerformance.html')
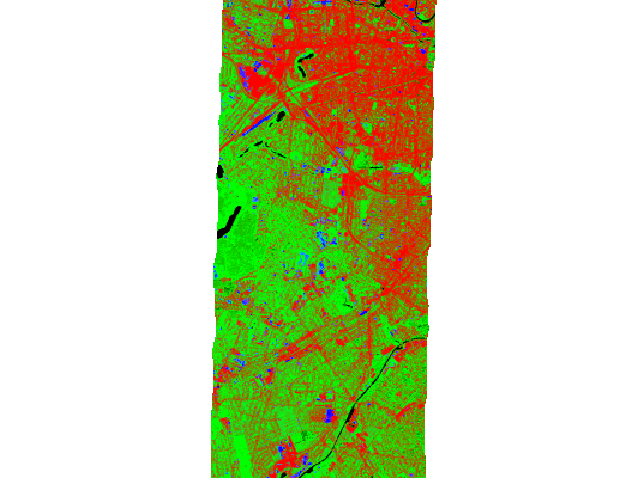
Random Forest (multi target) regression as false-color-composition (Red=’impervious’, Green=’vegetation’ and Blue=’soil’ pixel fractions)
HTML report:
Clustering¶
Fit K-Means clusterer, apply to a raster and assess the performance¶
import enmapboxtestdata
from hubflow.core import *
# create (unsupervised) sample
raster = Raster(filename=enmapboxtestdata.enmap)
sample = Sample(raster=raster)
# fit clusterer
from sklearn.cluster import KMeans
clusterer = Clusterer(sklEstimator=KMeans(n_clusters=5))
clusterer.fit(sample=sample)
# cluster a raster
prediction = clusterer.predict(filename='kmeanClustering.bsq', raster=raster)
# asses accuracy
reference = Classification(filename=enmapboxtestdata.createClassification(gridOrResolution=raster.grid(), level='level_2_id', oversampling=5))
performance = ClusteringPerformance.fromRaster(prediction=prediction, reference=reference)
performance.report().saveHTML(filename='ClusteringPerformance.html')
| ..... | Classes |
|---|---|
| class 1 | |
| class 2 | |
| class 3 | |
| class 4 | |
| class 5 |
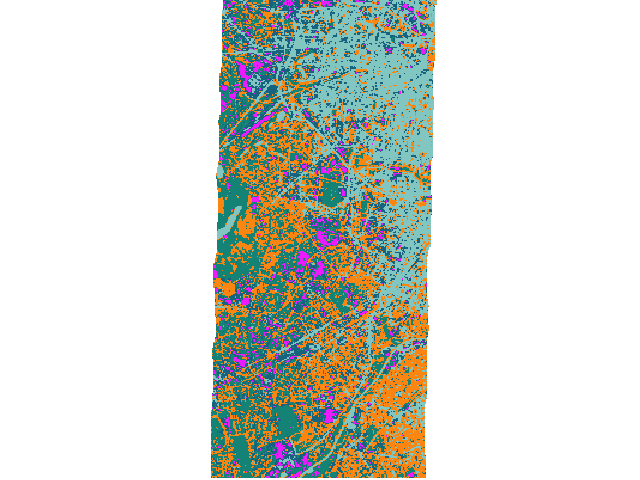
K-Means clustering.
HTML report:
Transformer¶
Fit PCA transformer and apply to a raster¶
import enmapboxtestdata
from hubflow.core import *
# create (unsupervised) sample
raster = Raster(filename=enmapboxtestdata.enmap)
sample = Sample(raster=raster)
# fit transformer
from sklearn.decomposition import PCA
transformer = Transformer(sklEstimator=PCA(n_components=3))
transformer.fit(sample=sample)
# transform a raster
transformation = transformer.transform(filename='transformation.bsq', raster=raster)
# inverse transform
inverseTransformation = transformer.inverseTransform(filename='inverseTransformation.bsq', raster=transformation)

PCA transformation as false-color-composition (Red=’pc 1’, Green=’pc 2’ and Blue=’pc 3’)

Reconstructed raster (inverse transformation of PCA transformation) as true-color-composition
Mask¶
Mask values inside valid range¶
import enmapboxtestdata
from hubflow.core import *
raster = Raster(filename=enmapboxtestdata.enmap)
mask = Mask.fromRaster(filename='mask.bsq', raster=raster, true=[range(0, 100)],
aggregateFunction=lambda a: np.any(a, axis=0))

Mask values outside valid range¶
import enmapboxtestdata
from hubflow.core import *
raster = Raster(filename=enmapboxtestdata.enmap)
mask = Mask.fromRaster(filename='mask.bsq', raster=raster, false=[range(0, 100)], initValue=True,
aggregateFunction=lambda a: np.all(a, axis=0))

Mask water bodies from classification¶
import enmapboxtestdata
from hubflow.core import *
# create classification
classification = Classification(filename=enmapboxtestdata.createRandomForestClassification())
print(classification)
# create mask for water bodies (id=5)
mask = Mask.fromRaster(filename='mask.bsq', raster=classification, true=[5])

Apply mask to raster¶
import enmapboxtestdata
from hubflow.core import *
# mask out all pixel that are covered by the vector
raster = Raster(filename=enmapboxtestdata.enmap)
mask = VectorMask(filename=enmapboxtestdata.landcover_polygons)
maskedRaster = raster.applyMask(filename='maskedRaster.bsq', mask=mask)
# mask out all pixel that are NOT covered by the vector
mask2 = VectorMask(filename=enmapboxtestdata.landcover_polygons, invert=True)
maskedRaster2 = raster.applyMask(filename='maskedRaster2.bsq', mask=mask2)

Raster masked by vector.

Raster masked by inverted vector.
EnviSpectralLibrary¶
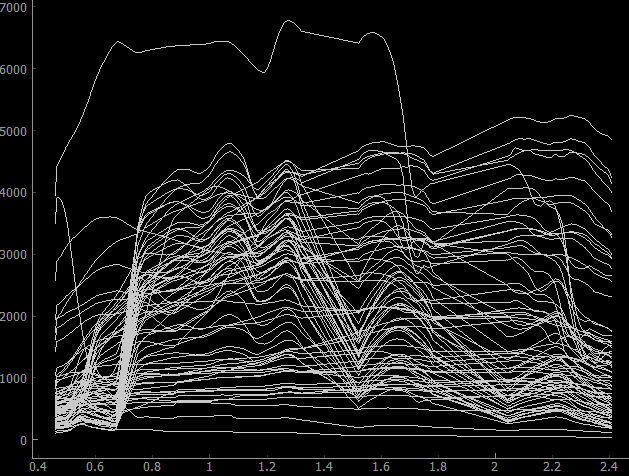
Read profiles and metadata from library¶
import enmapboxtestdata
from hubflow.core import *
# open library
speclib = EnviSpectralLibrary(filename=enmapboxtestdata.library)
# treat library as raster with shape (wavelength, profiles, 1)
raster = speclib.raster()
# read profiles
print(raster.dataset().array().shape)
# read metadata
print(raster.dataset().metadataItem(key='wavelength', domain='ENVI', dtype=float))
Prints:
(177, 75, 1)
[0.46, 0.465, 0.47, 0.475, 0.479, 0.484, 0.489, 0.494, 0.499, 0.503, 0.508, 0.513, 0.518, 0.523, 0.528, 0.533, 0.538, 0.543, 0.549, 0.554, 0.559, 0.565, 0.57, 0.575, 0.581, 0.587, 0.592, 0.598, 0.604, 0.61, 0.616, 0.622, 0.628, 0.634, 0.64, 0.646, 0.653, 0.659, 0.665, 0.672, 0.679, 0.685, 0.692, 0.699, 0.706, 0.713, 0.72, 0.727, 0.734, 0.741, 0.749, 0.756, 0.763, 0.771, 0.778, 0.786, 0.793, 0.801, 0.809, 0.817, 0.824, 0.832, 0.84, 0.848, 0.856, 0.864, 0.872, 0.88, 0.888, 0.896, 0.915, 0.924, 0.934, 0.944, 0.955, 0.965, 0.975, 0.986, 0.997, 1.007, 1.018, 1.029, 1.04, 1.051, 1.063, 1.074, 1.086, 1.097, 1.109, 1.12, 1.132, 1.144, 1.155, 1.167, 1.179, 1.191, 1.203, 1.215, 1.227, 1.239, 1.251, 1.263, 1.275, 1.287, 1.299, 1.311, 1.323, 1.522, 1.534, 1.545, 1.557, 1.568, 1.579, 1.59, 1.601, 1.612, 1.624, 1.634, 1.645, 1.656, 1.667, 1.678, 1.689, 1.699, 1.71, 1.721, 1.731, 1.742, 1.752, 1.763, 1.773, 1.783, 2.044, 2.053, 2.062, 2.071, 2.08, 2.089, 2.098, 2.107, 2.115, 2.124, 2.133, 2.141, 2.15, 2.159, 2.167, 2.176, 2.184, 2.193, 2.201, 2.21, 2.218, 2.226, 2.234, 2.243, 2.251, 2.259, 2.267, 2.275, 2.283, 2.292, 2.3, 2.308, 2.315, 2.323, 2.331, 2.339, 2.347, 2.355, 2.363, 2.37, 2.378, 2.386, 2.393, 2.401, 2.409]
Create labeled library from raster and vector points¶
import enmapboxtestdata
from hubflow.core import *
# open raster and vector points
enmap = Raster(filename=enmapboxtestdata.enmap)
points = VectorClassification(filename=enmapboxtestdata.landcover_points, classAttribute='level_2_id')
# rasterize points onto raster grid
classification = Classification.fromClassification(classification=points, grid=enmap.grid(), filename='/vsimem/classification.bsq')
# create classification sample
sample = ClassificationSample(raster=enmap, classification=classification)
# create ENVI spectral library from sample
speclib = EnviSpectralLibrary.fromSample(sample=sample, filename='speclib.sli')